在odoo开发的过程中,经常会出现对数据进行全文搜索的需求,而odoo本身是高度集成了postgreSql。尽管pgsql支持全文搜索的功能,但是pgsql承担了odoo的绝大多数业务数据存储,压力相对交大,我们希望让pgsql专心去做业务数据的处理,进而使用第三方引擎来支持全文搜索。有关全文搜索的搜索引擎,第一时间当然就是想到Elasticsearch。
整体架构 ElasticSearch安装 1)安装分词器找到你的es安装目录的bin目录下,执行以下命令安装中文ik分词器
记得切换你的es启动用户。
注意:如果你是集群安装es,要把每个节点的es都安装ik分词器
su es ./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.6.0/elasticsearch-analysis-ik-7.6.0.zip
安装好后记得kill -9 杀死es进程然后重启
2)测试分词器首先创建一个测试索引,测试分词器到底安装成功了没有
PUT test
POST test/_analyze
{
"analyzer": "ik_smart",
"text": "测试语句分词,测一测ik分词器到底行不行"
}
最终输出的分词结果应该是
{
"tokens" : [
{
"token" : "测试",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "语句",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "分词",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "测",
"start_offset" : 7,
"end_offset" : 8,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "一测",
"start_offset" : 8,
"end_offset" : 10,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "ik",
"start_offset" : 10,
"end_offset" : 12,
"type" : "ENGLISH",
"position" : 5
},
{
"token" : "分词器",
"start_offset" : 12,
"end_offset" : 15,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "到底",
"start_offset" : 15,
"end_offset" : 17,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "行不行",
"start_offset" : 17,
"end_offset" : 20,
"type" : "CN_WORD",
"position" : 8
}
]
}
odoo编写es工具类
ES安装好了以后,剩下的任务就是如何将odoo的数据和ElasticSearch进行同步,首先我们要选择操作包,python操作es的包是elasticsearch,因为我安装的版本是elasticsear7.6,因此选择elasticsear7这个包。
pip3 install elasticsearch7
在业务设计中,经常有可能在两个不同的模型中,会有同名的字段出现,而如果要将这些字段全部放在同一个es索引下,会导致字段重名而产生各种错误,为了解决这个问题,我采用了字段映射的方式,用模型名和字段名做key,去映射es里面的一个唯一字段。
index_filed_list = {
("product", "product_name"): "product_name",
("product", "comment"): "product_comment",
("product", "solution"): "product_solution",
("company", "company_name"): "company_name",
("company", "founder"): "company_founder",
("company", "comment"): "company_comment",
("sales", "name"): "sale_names",
}
我们在odoo.conf中配置好es的ip、端口和索引,在代码中去获取这个配置信息。
import odoo.tools host = odoo.tools.config['es_host'] port = odoo.tools.config['es_port'] index = odoo.tools.config['index_name']
接下来就要去实现Es的工具类了,首先创建一个Es的相关模型,并且禁止他去pgsql中创建表。
# -*- coding: utf-8 -*-
from odoo import models, api
from elasticsearch7 import Elasticsearch
import odoo.tools
host = odoo.tools.config['es_host']
port = odoo.tools.config['es_port']
index = odoo.tools.config['index_name']
index_filed_list = {
("product", "product_name"): "product_name",
("product", "comment"): "product_comment",
("product", "solution"): "product_solution",
("company", "company_name"): "company_name",
("company", "founder"): "company_founder",
("company", "comment"): "company_comment",
("sales", "name"): "sale_names",
}
class ElasticSearchUtil(models.AbstractModel):
_description = 'es工具类'
_name = 'prod.util.elasticsearch'
_auto = False
实现一个静态的获取es实例的方法
@staticmethod
def get_es_instance():
return Elasticsearch([{'host': host, 'port': port}], http_auth=())
考虑到有可能索引是未创建的状态,因此先检查一下索引是否存在,如果不存在则创建一个新索引
@api.model
def create_index(self, es):
# 判断索引是否存在,不存在就创建一个
if not es.indices.exists(index=index):
es.indices.create(index=index)
在某些特殊情况,我们需要删掉索引强制重建
@api.model
def delete_index(self):
# 存在就给他删了
es = self.get_es_instance()
if es.indices.exists(index=index):
es.indices.delete(index=index)
es默认的分词器是不支持中文的,因此在遇到新的字段时,必须显式的创建mapping并支持中文分词,这里我们使用ik分词器。
@api.model
def get_fileds_mapping_or_create(self, es, fileds):
# 判断这些字段的mapping是否存在,不存在就创建
mapping_dict = es.indices.get_mapping(index=index).get(index).get('mappings')
if mapping_dict.get('properties'):
mapping_list = mapping_dict.get('properties').keys()
else:
mapping_list = []
body = {
"properties": {
}
}
update_mapping = False
for filed in fileds:
if filed not in mapping_list:
update_mapping = True
body['properties'][filed] = {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
if update_mapping:
es.indices.put_mapping(index=index, body=body)
在实际的业务过程中,新插入一条数据,可以直接在es中创建一个文档,而如果有对数据的修改,es的包可不支持直接的修改,需要写一个修改的json,我们这里把修改字段内容的方法封装一下
@api.model
def update_filed_by_id(self, es, id, fileds: dict):
# 更新一条数据
update_str = ';'.join([f"ctx._source.{key}='{value}'" for key, value in fileds.items()])
body = {
"script": {
"source": update_str
}
}
es.update(index=index, id=id, body=body)
对于数据的删除,有两种情况,一种情况是该数据是一对多存储的,删除这条数据,只会删除索引中的其中一部分,属于文档数据修改。另一种情况是该数据是一对一存储,应该直接删除该字段。
@api.model
def delete_filed(self, ids, model_name):
# 删除某些字段
fileds = []
for key in index_filed_list.keys():
if key[0] == model_name:
fileds.append(index_filed_list.get(key))
es = self.get_es_instance()
delete_str = ';'.join([f"ctx._source.remove('{item}')" for item in fileds])
for id in ids:
body = {
"query": {
"term": {
"_id": f"{id}"
}
},
"script": {
"source": delete_str
}
}
es.update_by_query(index=index, body=body)
es.close()
前置的方法已经基本完成,现在开始实现同步pgsql字段和es索引的方法
@api.model
def insert_or_update_filed(self, ids, fileds: dict, model_name):
# 检查索引是否存在
es = self.get_es_instance()
self.create_index(es)
body = {}
update_value = False
for key, value in fileds.items():
# 只有字符类型的才建索引
if (model_name, key) in index_filed_list.keys():
update_value = True
body[index_filed_list.get((model_name, key))] = value
if update_value:
self.get_fileds_mapping_or_create(es, body.keys())
# 检查该id的记录是否存在
for id in ids:
if not es.exists(index=index, id=id):
es.index(index=index, doc_type='_doc', id=id, refresh=True, body=body)
else:
self.update_filed_by_id(es, id, body)
es.close()
至此,es工具类基本实现。
重写odoo模型的增删改方法在其他的模型中,我们需要重写odoo的增删改方法,进而实现在对模型进行增删改操作时,es的索引能够同步进行修改。
# 重写模型创建方法,创建模型时同步创建es相关文档
@api.model
def create(self, vals):
result = super().write(vals)
self.env['prod.util.elasticsearch'].insert_or_update_filed(result.ids, vals, "company")
return result
# 重写模型修改方法,创建模型时同步修改es相关文档
def write(self, vals):
self.env['prod.util.elasticsearch'].insert_or_update_filed(self.ids, vals, "company")
return super().write(vals)
# 重写模型删除方法,创建模型时同步删除es相关文档
def unlink(self):
self.env['prod.util.elasticsearch'].delete_filed(self.ids, "company")
return super().unlink()
注意,这样进行操作之后,每次修改都必须使用odoo的self.create/write/unlink方法,如果直接执行pgsql的话,还是会跳过es的索引同步,导致es索引和pgsql中索引不一致,面对这种情况,我们需要重写一个强制完全重建索引的方法,来保证索引的一致性。
这里强制重建索引的代码和业务相关性比较大,需要根据自己的业务需求自行调整。
@api.model
def rebuild_elasticsearch_index(self):
# 强制重建索引方法
self.env['prod.util.elasticsearch'].delete_index()
prod_ids = self.search([('id', '!=', None)]).ids
for prod_id in prod_ids:
prod = self.search_read([('id', '=', prod_id)])[0]
# 判断是否有选择公司
if prod.get('company'):
company = self.env['prod.company'].search_read([('id', '=', prod.get('company')[0])])
self.env['prod.util.elasticsearch'].insert_or_update_filed([prod.get('id')], company[0], "company")
# 判断是否选择了销售
if prod.get('sales_emp'):
sale_ids = prod.get('sales_emp')
sales = self.env['prod.sales'].search([('id', 'in', sale_ids)])
sale_names = []
for s in sales:
sale_names.append(s.name)
self.env['prod.util.elasticsearch'].insert_or_update_filed([prod.get('id')],{'name': ','.join(sale_names)}, "sales")
# 更新本体的索引字段
self.env['prod.util.elasticsearch'].insert_or_update_filed([prod.get('id')], prod, "product")
搜索方法
千万不要忘了,我们使用es做第三方的索引,目的就是进行全文搜索,现在来实现一个全文搜索的方法。
需要对es的语法有一定的了解,使用bool:{should:{}}来进行多个条件的或运算,使用match的方法,可以对字段进行分词索引,如果不需要分词的字段,可以使用term:{value:filed.keyword}的方式进行匹配。
匹配的结果记得要加上highlight,确定具体匹配到了哪些词语。最后再从pgsql中取出不在索引内的字段,把整体返回结果封装一下就可以了。
@api.model
def search_info_by_keyword(self, keyword, size, page):
es = self.get_es_instance()
values = index_filed_list.values()
match_query_list = [{"match": {value: keyword}} for value in values]
highlight_query_dict = {value: {} for value in values}
body = {
"query": {
"bool": {
"should": match_query_list
}
},
"highlight": {
"fields": highlight_query_dict
},
"size": size,
"from": (page - 1) * size
}
result = {
"info": [],
'total': 0
}
hits = es.search(index=index, body=body)['hits']
search_result = hits['hits']
for info in search_result:
fileds = info['_source']
info_highlight = info['highlight']
if "company_name" in info_highlight.keys():
company_name = info_highlight['company_name'][0]
del info_highlight['company_name']
else:
company_name = fileds.get('company_name')
if "product_name" in info_highlight.keys():
product_name = info_highlight['product_name'][0]
del info_highlight['product_name']
else:
product_name = fileds.get('product_name')
if len(info_highlight) > 0:
highlight = '...'.join(value[0] for value in info_highlight.values())
else:
if "product_comment" in fileds:
highlight = fileds.get('product_comment')
elif "company_name" in fileds:
highlight = fileds.get('company_name')
elif "product_solution" in fileds:
highlight = fileds.get('product_solution')
else:
highlight = None
prod = self.env['prod.product'].search([('id', '=', info['_id'])])
logo = prod.img
logo_name = prod.file_name
logo = self.env['prod.picture'].picture_add_base64_head({'logo': logo, 'file_name': logo_name},
{'logo': 'file_name'})
result['info'].append({
"id": info['_id'],
"company_name": company_name,
"product_name": product_name,
"highlight": highlight,
"logo": logo.get('logo'),
})
result['total'] = hits['total']['value']
return result
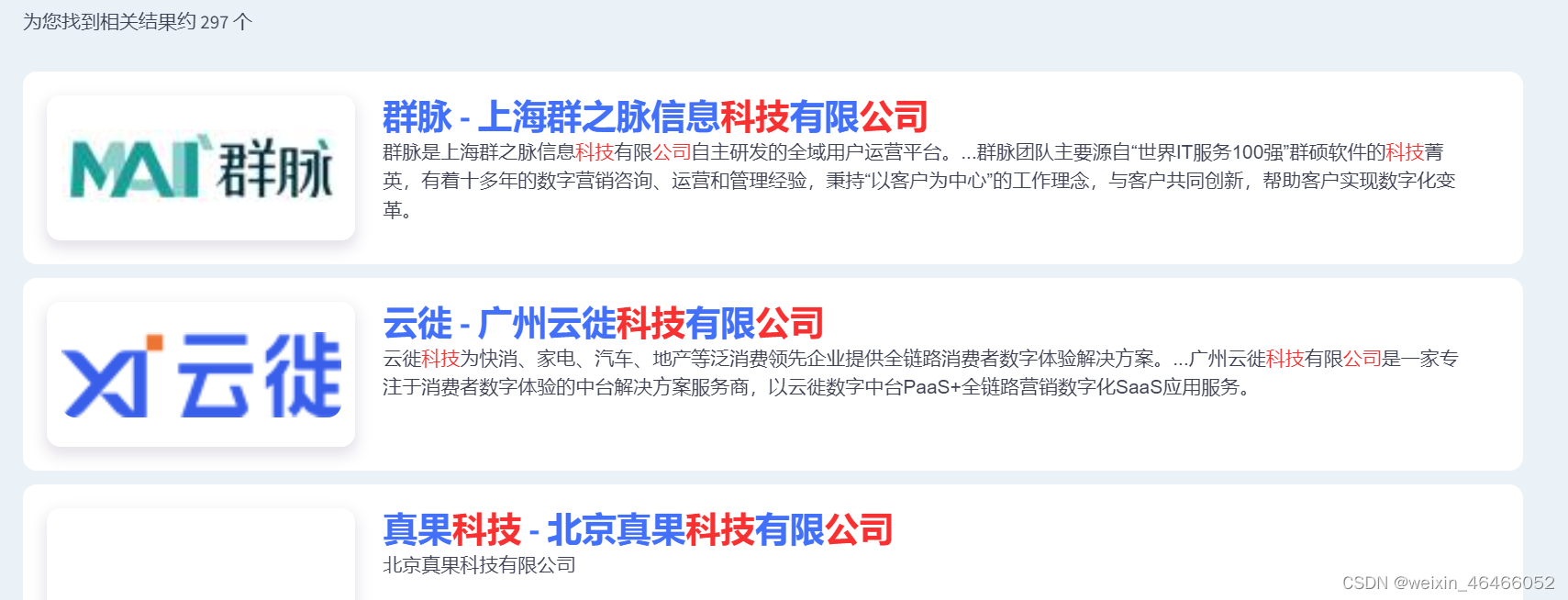
搜索效果
看一下搜索的效果如何,是否符合预期呢?
{'logo': 'file_name'})
result['info'].append({
"id": info['_id'],
"company_name": company_name,
"product_name": product_name,
"highlight": highlight,
"logo": logo.get('logo'),
})
result['total'] = hits['total']['value']
return result
# 搜索效果 看一下搜索的效果如何,是否符合预期呢?