


++n
n++区别
1.概念int n=1,n1,n2;
n1=++n;
System.out.println(n1);
System.out.println(n);
n2=n++;
System.out.println(n2);
System.out.println(n);
2
2
2
3
写算法的哲学:
由简单到复杂:验证一步走一步,多打印中间结果
先局部后整体:没思路的时候先细分
先粗糙后精细:变量更名,语句合并,边界处理(length-1 length-2这种都是试的,可以先写一个不要纠结,提炼方法
调bug的哲学:
第一步:通读程序 确认理解了整个程序的逻辑 并且你读不出bug
第二步:如果还是有bug,输出中间值
第三步:如果还是有bug,减少功能 留下核心
最次的情况,光看不动手
算法:algorithm 同一个问题的不同解决方法 算法往往是针对特定的数据结构
数据结构:Data Structure 存储数据的不同方式 一管子苹果 (数组中间没空隙无法插入数据 链表可以插入数据)一篮子苹果
查找对于数组来说要比链表快的多 链表要顺着链子一个个往下找
Big O:判定算法的好坏 学术上的时间表示
时间测算:时间越短越好 时间是通过时间差来计算(System.currentTimeMillis()分别打印出开始时间和结束时间) 但是针对一些不是很复杂的算法的话 时间差可能都是四舍五入到1s,这个时间可以把算法放在循环里面,增加时间,就是所谓的 幅度不够 循环来凑
空间测算:数篮子里的苹果需要借助另外一个篮子 就是占用了别的空间 占的空间越少 这个算法越好
时间复杂度:时间的复杂程度 就是随着问题规模的扩大 时间的变化规律
O(忽略掉系数高阶项)
样本足够大,那些都不太重要,所以可以忽略
代表的就是最差时间复杂度
还有平均和最好,这些面试都不考的
空间复杂度:就是随着问题规模的扩大 空间的变化规律 看的是额外空间 而不是问题所必须的空间 变量的分配不去考虑,必须要分配的那些局部变量等不计入空间复杂度之内
不需要考虑的操作:赋初始值 程序初始化
忽略:O(2n)和O(n)是差不多的,忽略2 O(n^2+2n),也是直接忽略2n
eg1.对于一个大小为10的数组和一个大小为10000的数组来说,访问数组的最后一个元素并不会有什么差别
也就是随着问题规模的扩大,时间基本不会变化 用O(1)来表示 ,一个常数
eg2.对于访问链表的某个位置的话(如果都是位置1呢么肯定也是O(1),但是我们一般讲时间复杂度都是讲最差的情况),所以假设为访问链表最后一个位置的值 规模为10 1s 规模为100 10s O(n) 线性的变化
最常见的就是O(1)和O(n),若是对访问链表的最后一个位置进行两遍循环就是O(n2),三遍循环就是O(n3)
eg2:求一个数组的平均数的时间复杂度
O(n) 因为要把数组的所有数给加起来
2.排序(sort)排序就是给一组没有顺序的数,按从小到大或者从大到小排列好
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t1XPpyBk-1638342991072)(C:Users密西西比的守望AppDataRoamingTyporatypora-user-imagesimage-20210308114914739.png)]
最重要的四种是:插排 堆排 归并 快排
选泡插
快归堆希统计基
恩方恩老恩一三
对恩加k恩乘k
不稳稳稳不稳稳
不稳不稳稳稳稳
2.1 选择排序所谓选择排序,就是不断选择出来最小(最大)
最简单也最没用(时间复杂度太高O(n^2)而且不稳定)的排序算法 有一定的优化空间
通过比较不断确定最小值的下标,这个下标是不断变化的,遍历一遍确定最小值的下标和第一个位置上的值交换,第二次遍历是从第二个数开始,然后和第二个值交换,依次类推。
1.处理过程
package com.liu.algorithm.sort;
public class SelectionSort {
public static void main(String[] args) {
int[] arr={4,3,5,1,9,6,7,2,8};
//优化一:处理边界值,arr.length改成arr.length-1,外层循环少循环一次
for (int i=0;i
2.完整代码
package com.liu.algorithm.sort;
public class SelectionSort_1 {
public static void main(String[] args) {
int[] arr = {31, 33, 38, 22, 45, 16, 90, 35, 90};
for (int i = 0; i < arr.length - 1; i++) {
int minPostion = i;
for (int j = i + 1; j < arr.length; j++) {
minPostion = arr[j] < arr[minPostion] ? j : minPostion;
}
swap(arr, i, minPostion);
System.out.println("这是第" + (i + 1) + "循环之后的结果");
print(arr);
System.out.println();
}
System.out.println("======这是最终的结果======");
print(arr);
}
static void swap(int[] arr, int i, int j) {
int temp = arr[j];
arr[j] = arr[i];
arr[i] = temp;
}
static void print(int[] arr) {
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " ");
}
}
}
(1)bigO分析
找到最消耗时间的那个进行分析即可,不需要全部分析,如果两个for循环,就看两个for循环中间套的呢个语句的执行时间就行了
最好和最差的都是O(n^2) 所谓最好的就是已经排序好,但是仍然需要把数组里面的所有数都遍历一遍
空间复杂度O(1) 说明不占用额外的空间
不稳定 就是两个相等的数进行排序 他们排完序后的相对顺序有可能改变
如何证明选择排序不稳定:
5 6 5 2 1 这里面第二个5的顺序就会排在第一个5的前面
不稳定所导致的后果:如果同样作为银行客户的小王和老王,年龄一样,但是在银行的存款和会员等级不一样,那么如果顺序颠倒了,可能会导致银行的某种业务逻辑被打乱,比如说,同样年龄的情况下,会员等级高的人优秀办理,导致逻辑矛盾。
(2)验证算法-对数器
对数器:你写的和系统写的(Arrays.sort(arr);) 对比输出结果 就是一对数 就是对数器
如何验证算法正确与否?
- 肉眼观察(测试程序可以 真正的工程计算不可以 不可能枚举出所有情况)
- 产生足够多的随机样本
- 用确定正确的算法计算样本结果
- 用自己的算法验证一遍 对比验证结果
2.2 冒泡排序
冒泡就是两两比较 达到将最小或最大的数排到最后的目的
空间复杂度:O(1) 没用涉及到任何额外的空间
时间复杂度:O(n^2)
稳定性:稳定 两两比较的 不是像选择排序那种跳着比较的,有可能跳到后面去
优化冒泡排序:使之最好的时间复杂度是O(1)
2.3 插入排序(*)
对基本有序 的数组最好用 插入排序比冒泡排序快一倍 比选择排序要快
稳定
时间复杂度:
O(n^2) (6 5 4 3 2 1)比较n+n-1+n-2 + 1 等差数列
最好 O(n) 比较后发现不用动(1 2 3 4 5) 就不用交换
比较一次
空间复杂度:O(1)
插入排序就是从第二个元素开始直到最后一个元素,依次与前面一个元素进行比较插入 慢慢移动
有点像往前的冒泡排序
2.4 总结选择 冒泡 插入
打斗地主
选泡插 空间复杂度都是O(1) 时间复杂度都是O(n^2) 最好的后面两个是O(n)
冒泡:基本不用 两两比较 两两交换 太慢
选择:基本不用 不稳定
插入:样本小且基本有序的时候效率比较高
2.5 希尔排序
用的不是特别多 面试考希尔排序考的也不是特别多
改进的插入排序 希尔排序是特殊的插入排序,它的间隔>=1 普通插入排序的间隔为1
间隔大的时候,移动的次数比较少,移动的距离比较长 跳着排 不稳定
每隔一个间隔拿出一个数出来,组成一个新的数组
希尔排序的优化主要体现在间隔序列
刚开始是以数组长度的一半作为间隔序列 然后一半的一半,一半的一半这样下去
Knuth序列
h=3*h+1 h=1 1,4,7,10,13, h最大值<=整个数组长度的1/3
时间复杂度:最好O(n^1.3)
空间复杂度:O(1)
稳定性:
2.6 归并排序(*)
2.6.1 递归
一个方法在他内部的执行过程之中 调用方法自身 狗咬自己尾巴 严格来说不是同一个方法,因为参数不一样
递归需要有停止条件也就是base case
package com.liu.algorithm.sort;
public class Recursion {
public static void main(String[] args) {
System.out.println(f(10));
}
static long f(int n){
//没有这俩条件 会出现栈溢出的情况
if (n<1){
return -1;
}
if (n==1){
return 1;
}
return n+f(n-1);
}
}
运算结果:5
merge sort
Java对象排序专用(TIM SORT改进的归并排序)
不断分成一半,分到不能再分了(就是数组里面只有两个数或者一个数了) 然后合并 合并 (合并的前提是这两个数组已经排好序)
时间复杂度:因为不断的一分为二,对数函数
空间复杂度:
稳定性:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L7RhsKK3-1638342991079)(C:Users密西西比的守望AppDataRoamingTyporatypora-user-imagesimage-20210311165546356.png)]
java对象排序
- 对象排序一般要求稳定 对象属性多
2.7 快速排序(*)
单轴快排
双轴快排
现在有一个数组,以最后一个数为参照,小于它的放在左边,大于它的放在右边,左边和右边当然都是在这最后一个数的左边
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uWkTPohX-1638342991083)(C:Users密西西比的守望AppDataRoamingTyporatypora-user-imagesimage-20210311183813803.png)]
java内部的Array 双轴快排 这是快速排序的改进算法
Arrays.sort(arr);
2.8 计数排序
非比较排序 适用于一些特殊的情况
桶思想的一种
算法思想:量大范围小
- 某大型公司数万名员工的年龄排序 18-80
- 高考分数 0-750
每个数出现的次数作为新数组的的元素值,值的大小作为新数组的下标值,然后再把这些数从小到大重新组成一个新数组
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yCLBv4OP-1638342991085)(C:Users密西西比的守望AppDataRoamingTyporatypora-user-imagesimage-20210312123125951.png)]
结果数组:0012222233344555666666677777777899
空间复杂度:n+k(k个桶)
时间复杂度:n+k(n)
2.9 基数排序
非比较排序
桶思想的一种
多关键字排序
个位先排,依次是十位,百位
空间复杂度:O(n)
时间复杂度:O(n)
稳定排序
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gDocPa6Q-1638342991088)(C:Users密西西比的守望AppDataRoamingTyporatypora-user-imagesimage-20210312205357148.png)]
2.10 桶排序
最大值-最小值=差值 根据差值分桶 一个桶代表一个范围 每个桶单独排序
不重要
3.二分排序
在一个有序数组中找某个数是否存在
不断砍一半
砍多少次一半
看2^(几次)=数组长度
几次=log2数组长度
复杂度就是(log2数组长度)=log2n
这个是log以2为底的意思
logn在计算机里面默认就是以2为底的
无序二分
4.异或
exclusive OR 缩写成xor或eor
不同为1 符号为^ 无进位相加
0^N== N
N^N===0
异或满足交换律和结合律(同样一批数异或起来的结果肯定是一样的)
同样位置只看 1的偶数个还是奇数个,跟顺序没有任何关系
异或的用法
题目一:int a=x;
int b=y;
让ab的值交换
a=a^b
b=a^b
a=a^b
就可以了
值相同这个还成立,但内存相同时候这个就不成立了
package com.liu.algorithm.erfen;
public class Demo {
public static void main(String[] args) {
int[] arrs={1,2,3};
swap(arrs,0,0);
System.out.println(arrs[0]);
System.out.println(arrs[1]);
}
public static void swap(int[] arrs,int i,int j){
arrs[i]=arrs[i]^arrs[j];
System.out.println("arr[0]="+arrs[0]);
arrs[j]=arrs[i]^arrs[j];
System.out.println("arr[0]="+arrs[0]);
arrs[i]=arrs[i]^arrs[j];
}
}
题目2:
一个数组里面,只有一个数是奇数个,其他数都是偶数个
求这个数
把数组里面的数都拿出来异或,最结果就是这个数
偶数个数之间异或结果都是0
奇数个最剩一个
int xor=0;
int xor=xor^a[0]
int xor=xor^a[1]
.
.
int xor =xor^a[n]
题目3:
二进制数N,取它最右边1
N&(取反N+1)
题目4:
一组数中有两个数出现了奇数次,其余的数都出现了偶数次,求这两个数
int xor=a^b!=0
所以xor的第t位一定是1,所以要么a的第t位是1,要么b的第t位为1.(找最右侧为1的确定t位置,其实不用找最右侧为1,任何一个1就可以了)
把整组数分为两组,一组是第t位为1,一组是第t位为0.
异或其中一组,得到的就是a或b,xor',则另一个数就是xor^xor'
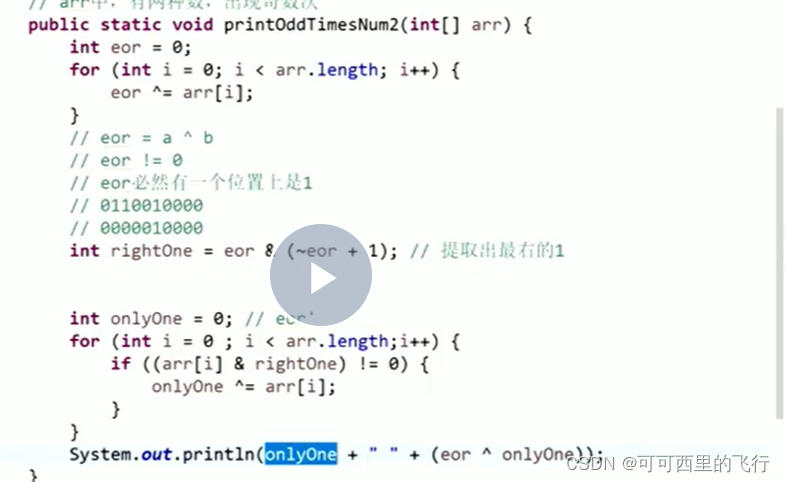
拓展:
找到一个数中,有多少个1
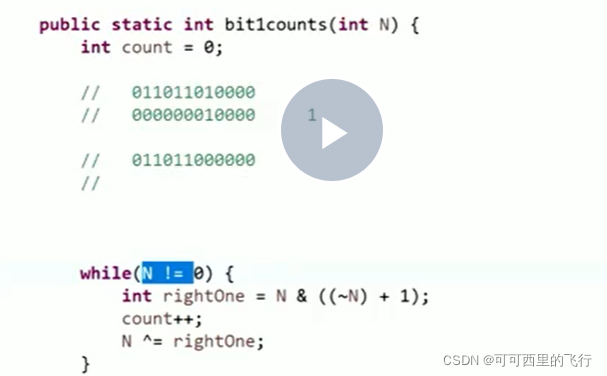
# 二.数据结构
非比较排序 适用于一些特殊的情况
桶思想的一种
算法思想:量大范围小
- 某大型公司数万名员工的年龄排序 18-80
- 高考分数 0-750
每个数出现的次数作为新数组的的元素值,值的大小作为新数组的下标值,然后再把这些数从小到大重新组成一个新数组
[外链图片转存中...(img-yCLBv4OP-1638342991085)]
结果数组:0012222233344555666666677777777899
空间复杂度:n+k(k个桶)
时间复杂度:n+k(n)
## 2.9 基数排序
非比较排序
桶思想的一种
多关键字排序
个位先排,依次是十位,百位
空间复杂度:O(n)
时间复杂度:O(n)
稳定排序
[外链图片转存中...(img-gDocPa6Q-1638342991088)]
## 2.10 桶排序
最大值-最小值=差值 根据差值分桶 一个桶代表一个范围 每个桶单独排序
不重要


